RAM
Jolt proves the correctness of RAM operations using the Twist memory checking algorithm, specifically utilizing the "local" prover algorithm.
Dynamic parameters
In Twist, the parameter determines the size of the memory. For RAM, unlike registers, is not known a priori and depends on the memory usage of the guest program. Consequently, the parameter , dictating how the memory address space is partitioned into chunks, must also be dynamically tuned. This ensures that no committed polynomial exceeds a maximum size defined by .
Jolt is currently configured so that if and otherwise. Using smaller gives better prover performance for shorter trace lengths.
Address remapping
We treat each 8-byte-aligned doubleword in the guest memory as one "cell" for the purposes of memory checking.
Our RISC-V emulator is configured to use 0x80000000 as the DRAM start address -- the stack and heap occupy addresses above the start address, while Jolt reserves some memory below the start address for program inputs and outputs.
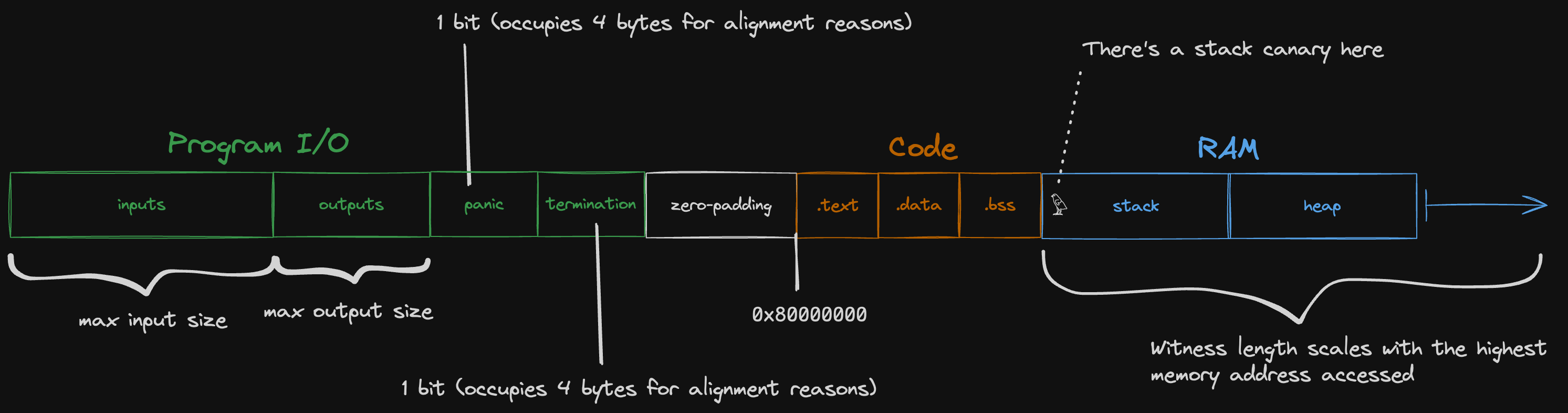
For the purposes of the memory checking argument, we remap the memory address to a witness index:
#![allow(unused)] fn main() { (address - memory_layout.lowest_address) / 8 }
where lowest_address is the left-most address depicted in the diagram above.
The division by eight reflects the fact that we treat guest memory as "doubleword-addressable" for the purposes of memory-checking.
Any load or store instructions that access less than a full doubleword (e.g. LB, SH, LW) are expanded into inline sequences that use the LD or SD instead.
Deviations from the Twist algorithm as described in the paper
Our implementation of the Twist prover algorithm differs from the description given in the Twist and Shout paper in a couple of ways. One such deviation is wv virtualization. Other, RAM-specific deviations are described below.
Single operation per cycle
The Twist algorithm as described in the paper assumes one read and one write per cycle, with corresponding polynomials (read address) and (write address). However, in the context of the RV64IMAC instruction set, only a single memory operation -- either a read or a write (or neither) -- is performed per cycle. Thus, a single polynomial (merging and ) suffices, simplifying and optimizing the algorithm. This polynomial is referred to as for the rest of this document.
No-op cycles
Many instructions do not access memory, so we represent them using a row of zeros in the polynomial rather than the one-hot encoding of the accessed address. Having more zeros in makes it cheaper to commit to and speeds up some of the other Twist sumchecks. This modification necessitates adjustments to the Hamming weight sumcheck, which would otherwise enforce that the Hamming weight for each "row" in is 1.
We introduce an additional Hamming Booleanity sumcheck:
where is the Hamming weight polynomial, which can be virtualized using the original Hamming weight sumcheck expression:
For simplicity, these equations are presented for the case, but as described above, for RAM is dynamic and can be greater than one.
ra virtualization
In Twist as described in the paper, a higher parameter would translate to higher sumcheck degree for the read checking, write checking, and evaluation sumchecks. Moreover, is fundamentally incompatible with the local prover algorithm for the read/write checking sumchecks.
To leverage the local algorithm while still supporting , Jolt simply carries out the read checking, write checking, and evaluation sumchecks as if , i.e. with a single (virtual) polynomial.
At the conclusion of these sumchecks, we are left with claims about the virtual polynomial. Since the polynomial is uncommitted, Jolt invokes a separate sumcheck that expresses an evaluation in terms of the constituent polynomials. The polynomials are, by definition, a tensor decomposition of , so the "ra virtualization" sumcheck is the following:
Advice Inputs
The evaluation sumcheck in Twist requires both the prover and verifier to know the initial state of the lookup table. When advice inputs are present in the RAM lookup table, the verifier doesn't have direct access to these values. To address this, the prover provides evaluations of the advice inputs and later proves their correctness against commitments held by the verifier.
For trusted advice, the commitment is generated externally; for untrusted advice, the prover generates the commitment. All advice inputs are placed at the lowest addresses of the RAM lookup table, with the larger advice type placed first to minimize field multiplications during verification.
We represent advice inputs and the RAM lookup table as multi-linear polynomials, assuming their sizes are powers of two.
Let:
- be the prover's RAM lookup table polynomial (including advice)
- be the verifier's RAM lookup table polynomial (zeros in advice section, otherwise identical to prover's)
- be the trusted advice polynomial
- be the untrusted advice polynomial
where (if this condition isn't met, we reorder the advice types to ensure the larger one comes first).
Let be the position of the single set bit in within its -bit representation. This position corresponds to bit when , or when .
The relationship between these polynomials is:
Since the verifier only needs to evaluate at a random point, it can compute this value efficiently using and the evaluations of the trusted and untrusted components.
Example
Consider a concrete example with:
- Total memory: 8192 elements ()
- Trusted advice: 1024 elements ()
- Untrusted advice: 128 elements ()
The memory layout would be:
- Addresses with the 3 MSBs as
000: trusted advice region (all combinations of the remaining 10 bits) - Addresses with the MSBs as
001000: untrusted advice region (all combinations of the remaining 7 LSBs)
This arrangement minimizes verifier computation. If we placed untrusted advice first, the verifier would need to check multiple bit patterns (000001, 000010, etc.) for the trusted section, resulting in significantly more field multiplications.
Output Check
Jolt ensures correctness of guest program outputs via the output check sumcheck. Guest I/O operations, including outputs, inputs, and termination or panic bits, occur within a designated memory region. At execution completion, outputs and relevant status bits are written into this region.
Verifying that the claimed outputs and status bits are correct amounts to checking that the following polynomials agree at the indices corresponding to the program I/O memory region:

Note that val_io is only contains information known by the verifier.
To check that these two polynomials are equal, we use the following sumcheck:
where is a "range mask" polynomial, equal to 1 at all the indices corresponding to the program I/O region and 0 elsewhere. The MLE for a range mask polynomial that isolates the range can be written as follows:
It is implemented in code as RangeMaskPolynomial.
This output check sumcheck generates a claim about the final memory state polynomial (), which, being virtual, is proven using the evaluation sumcheck:
Intuitively, the delta between the final and initial state of some memory cell is the sum of all increments to that cell.
The verifier also requires evaluations of the advice sections to compute . As with the evaluation described above, the prover provides these evaluations. Since both sumchecks use the same randomness, the prover only needs to provide one evaluation proof per advice type. If different randomness were used, separate proofs would be required for each sumcheck.
You may have noticed in the above expression that if a polynomial only over cyclce variables, while the book describes . This change is explained in wv virtualization.
Both the and evaluation sumchecks use the virtual polynomial, with claims subsequently proven via ra virtualization sumcheck.